


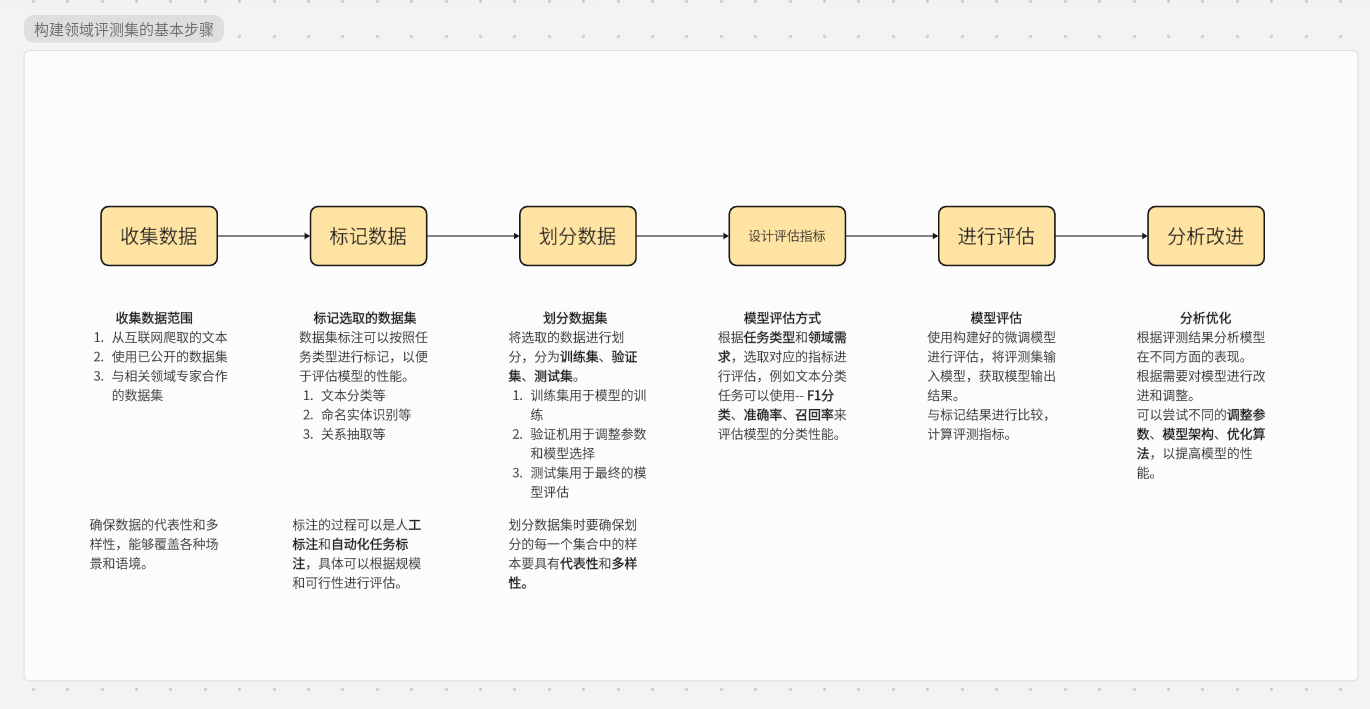
1.收集数据
首先需要收集与目标领域相关的数据。这可以包括从互联网上爬取文本数据、使用已有的公开数据、通过与领域专家合作来获取数据。
确保数据集具有代表性和多样性,能够涵盖领域中的各种情况和语境。
2.标注数据
对收集到的数据集进行标注,以便用于评测模型的性能。
标注可以根据任务类型来进行。如文本分类、命名实体识别、关系抽取等。
标注过程可以由人工标注或者使用自动化工具进行,具体取决于数据集的规模和可行性。
3.划分数据集
将标注好的数据集划分为训练集、验证集、测试集。
通常,训练集用于模型训练、验证集用于调整参数和模型选择,测试集用于最终评估模型的性能。
| 序号 | 名称 | 用途 |
|---|---|---|
| 1 | 训练集 | 用于模型训练 |
| 2 | 验证集 | 用于调整参数和模型选择 |
| 2 | 测试集 | 用于最终评估模型的性能 |
划分数据集要确保每个集合中的样本都具有代表性和多样性。
4.设计评测指标
根据任务类型和领域需求,选择合适的评测指标来评估模型的性能。
例如:对于文本分类任务,可以使用准确率、召回率、F1值等指标来衡量模型的分类性能。
5.进行评测
使用构建好的评测集对微调后的模型进行评测,将评测集输入模型,获取模型的预测结果,并与标注结果进行比较,计算评测指标。
6.分析和改进
根据评测结果,分析模型在不同方面的表现,并根据需要进行模型的改进和调整。
可以尝试不同的参数配置、模型框架、优化算法,以提高模型的性能。
7.流程图
评论区